Case Study - Schma.ai
A full-stack system for turning messy, real-time speech into structured, traceable outputs. Focused on low-latency pipelines, schema-driven parsing, and observability rather than naive LLM prompting.
- Date
- Roles
- Developer,
- Architect
- Tech
- TypeScript,
- Go,
- WebSocket,
- Remix,
- Google Cloud APIs,
- Supabase,
- Tailwind CSS,
- Shadcn/UI,
- Vercel,
- Fly.io,
- Docker
Origin & Motivation
My original motivation for Schma was personal and practical. I wanted to be able to speak naturally on the go (I'm often on the move) and have my words turned into usable, structured outputs that I could return to later. I strongly dislike manual data entry, and much of my day-to-day work as involves situations where typing simply isn't realistic (I work as a marine electrician as my day job).
When I looked for existing solutions, I found plenty of speech-to-text tooling, but very little infrastructure that helped you go from voice input to validated structured data in a way that could support real applications. Most tools stopped at transcription.Whereas very few addressed questions like traceability, correctness, or how a developer would actually build on top of the output.
That gap became the starting point for Schma.ai.
Problem Definition
At its core, Schma.ai was an attempt to solve a deceptively hard problem: How does one reliably extract structured data from messy speech... and how would they prove exactly where each value came from?
This turned out to be far more complex than simply attaching a schema to an LLM prompt and iteratively feeding it transcript chunks.
Real speech is noisy, ambiguous, and highly contextual. Meaning accumulates over time. Transcription is imperfect (although even real-time STT is edging towards being a commodity now), especially in noisy environments, and errors early in the pipeline can cascade into incorrect interpretation downstream (garbage in, garbage out).
At a system level, a number of challenges emerged quickly: Context must be accumulated and managed over the lifetime of a session, LLM calls introduce latency, retries, and backpressure, async requests can complete out of order, poor transcription quality can dramatically skew downstream parsing, and stateless or naive parsing strategies fail under real conditions.
For Schma.ai then, 'correctness' meant more than getting a plausible answer. Every structured value needed to be traceable back to the exact transcript segment(s) that produced it, validated against a known schema (JSON OpenAPI spec), and replayable later for debugging or audit. The system needed to explain why it produced an output, not just what it produced.
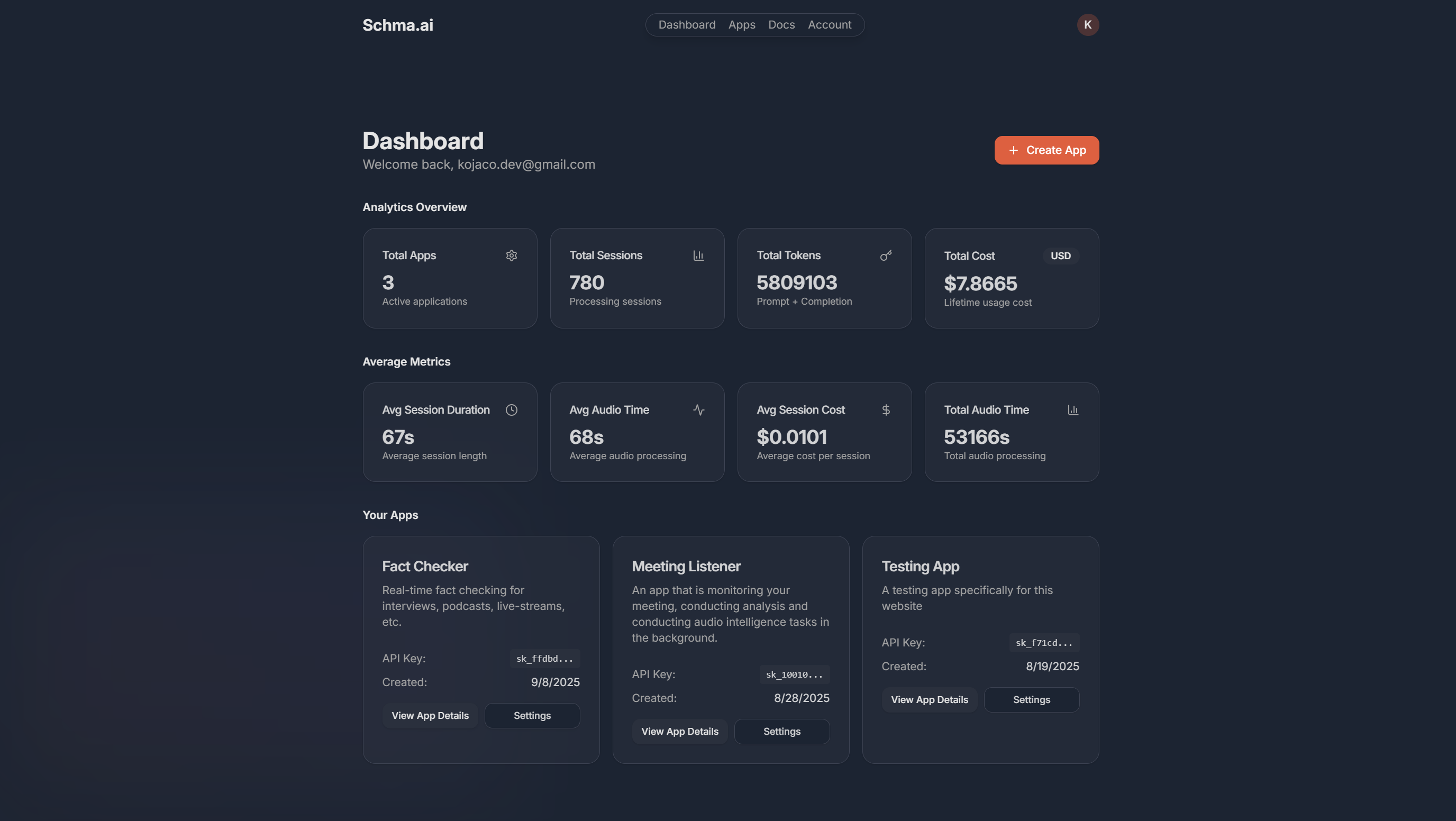
What I Built
Schma.ai evolved into a full backend platform rather than a narrow prototype (this was definitely me getting in over my head and approaching things incorrectly). The system included API key-based authentication and session management (server mint with JWT tokens, etc), a TypeScript WebSocket SDK with a React wrapper for frontend integration, and a Golang backend responsible for audio ingest, streaming speech-to-text, LLM orchestration, schema-aware parsing, and observability and metering.
Multiple parsing pipelines were implemented: structured output, function calling, and sensitive-data redaction and mapping via python sidecars using small quantised models like clinicalBERT / distilBERT. A batch processing mode was built on the same parsing pipeline.
I deliberately stopped before building a polished end-user application (although I did set something up for testing). Schma.ai was intended as infrastructure.. something developers could embed into their own products, rather than a vertical SaaS.
Architecture & System Design
On the client side, a TypeScript SDK handled authentication, audio capture, and communication with the backend. It was responsible for streaming audio chunks, emitting user-defined configuration (schemas, parsing strategy), and receiving transcripts, structured outputs, errors, and warnings. A lightweight silence detection mechanism (VAD) helped avoid unnecessary downstream processing by signalling 'silence' and halting the server pipeline / LLM calls.
The backend was implemented in Golang and followed an orthogonal (hexagonal) architecture. Core domain logic (entities, state machines, and ports) was isolated from infrastructure concerns like speech-to-text providers, LLM APIs, and persistence. Application orchestration lived separately from transport (HTTP and WebSocket), and reusable packages were factored out explicitly.
Transport was built around WebSockets. This choice was driven partly by speed to MVP (I've implemented websockets before), but more importantly by the need for true bidirectional communication. Client configuration could change mid-session (schemas could be updated, parsing strategies swapped for example) and that ruled out simpler unidirectional approaches like SSE (Server-Sent Events).
Key Design Decisions
One of the earliest and most consequential decisions was to pursue a real-time architecture. The goal was to support interactive use cases like live form filling and conversational agents. In practice, this introduced significant complexity, particularly around latency and concurrency. This ultimately outweighed the marginal value for most use cases.
Schema handling was another major focus. Users defined schemas in TypeScript, which then had to be translated into Go-compatible structures. This involved converting naming conventions and keeping definitions aligned across separate repositories (think camelCase convention in TS and snake_case convention in Go). The trade-off favored developer ergonomics over internal simplicity.
A particularly important design area was sensitive-data handling. The threat model I was addressing was leakage of protected health information into third-party LLM APIs without appropriate contractual safeguards (this was WAYYY too early for this project). To mitigate this, I implemented pre-LLM redaction. Sensitive values were replaced with placeholders (redacted entities via a python sidecar running clinicalBERT inference) before any external call, mapped in memory, and only restored for client display. Persisted data remained redacted. This allowed for auditability and compliance demonstrations without compromising developer usability.
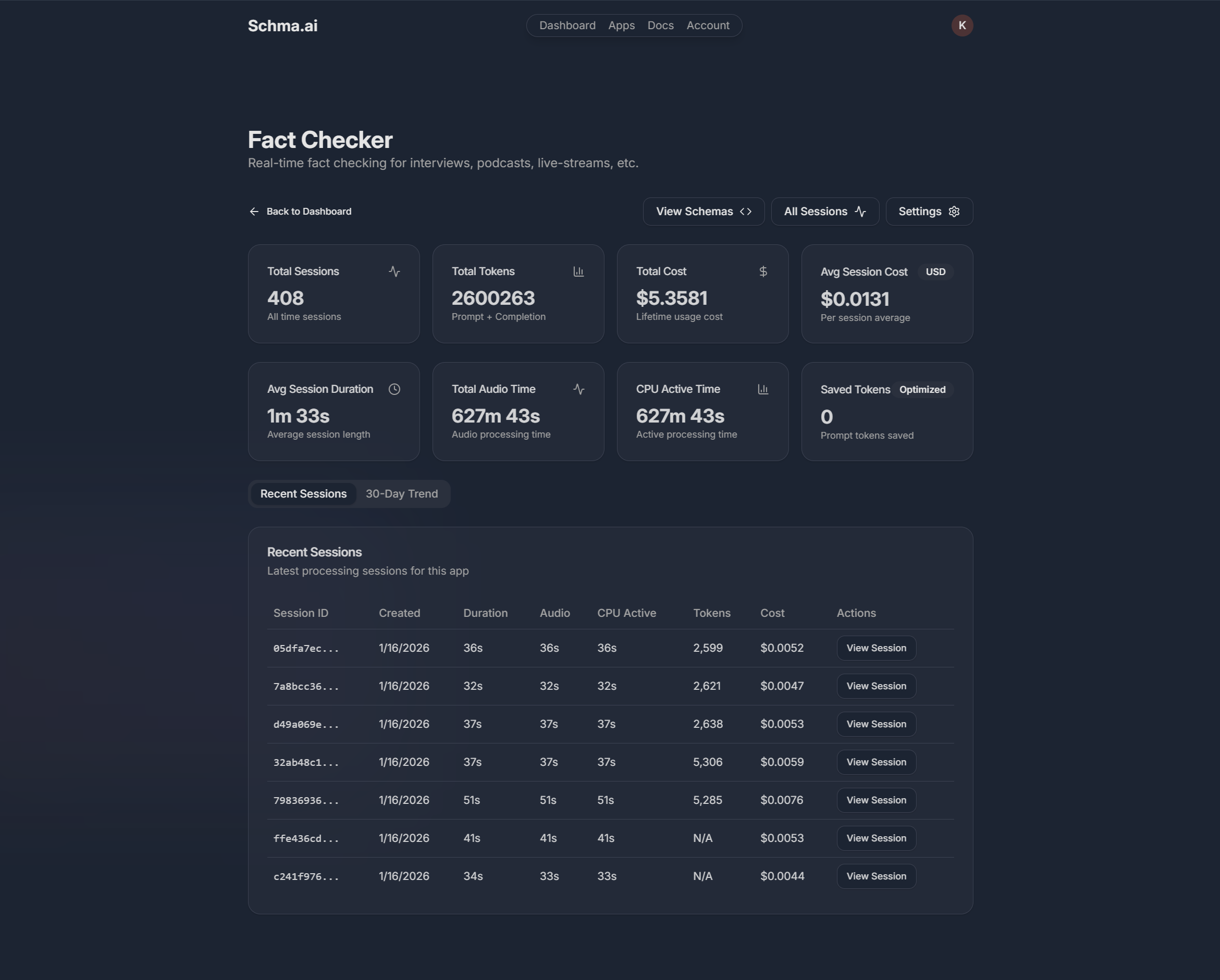
Observability, Traceability & Replayability
From the outset, Schma.ai treated observability as a first-class concern. Each session tracked metrics such as input and output token usage, STT duration, idle time, and LLM latency. Events, errors, and warnings were logged with timing information.
Crucially, the system was designed so that a session could be fully reconstructed after the fact. Developers could replay what was said, see exactly when LLM calls were made, and observe how structured outputs evolved over time.
Outcomes & Learnings
Schma.ai was paused after I entered the INCUBATE accelerator and attempted to validate it more formally. Through that process, it became clear that the project was far too broad and insufficiently niche. I had built a powerful system, but not one tightly aligned to a specific, validated problem (IMPORTANT).
From this, here are several important lessons / insights: Infrastructure depth should follow validated demand, not precede it. Real-time voice introduces enormous complexity that should be justified explicitly. Transport and STT layers are often better outsourced (for real-time, I would use something like LiveKit as the transport layer). A single, well-defined core flow is more valuable than maximal capability.
Rather than discarding the work, I reframed it as system discovery and will be using it as a foundation for a future projects.
What's Next
I am now refactoring Schma.ai into a much smaller, batch-first product focused on short audio inputs (under five minutes). The new direction prioritizes intent classification and structured extraction for daily workflows. It's geared towards capturing thoughts quickly and reviewing them later without manual entry.
Most of the infrastructure already exists. The work now is primarily about removing scope, simplifying flows, and shipping a small MVP in days rather than months.