Case Study - FactDat
An exploratory system for extracting and verifying factual claims from spoken content. It was focused on end-to-end 'claim checking', but the new focus should be on claim atomisation, traceability, and grounded reasoning
- Date
- Roles
- Developer,
- Researcher
- Tech
- LLM APIs,
- Speech-to-Text,
- NLP Pipelines,
- TypeScript
Problem Motivation
We are in an era where information spreads faster than people can realistically evaluate it. For low-stakes content, this is often harmless. For high-reach or high-impact content (elections, public health, geopolitics) misinformation and disinformation can propagate widely before anyone has time to respond, by which point the damage is already done.
The obvious reaction is to try to 'fact check everything'. In practice, that framing is too broad to be useful. Verification only works if you can first identify what is being claimed, who is making the claim, and where in the source material it appears.
If you can't reliably extract claims in a structured, traceable way, verification will always be fragile, no matter how sophisticated the model.
I started this project with the initial assumption that I could naively just extract claims and verify them end-to-end. However, it quickly became obvious that the issue of actually extracting a verifiable claim was MUCH more complex that I thought.
Problem Definition
A 'claim' is not simply a factual-looking sentence. Claims can be explicit or implied, spread across multiple sentences, dependent on speaker identity ('I never said...' - who dat?), mixed with opinion, sarcasm, or rhetorical framing, and underspecified without additional context.
For a claim to be meaningfully verifiable, it must be: Atomic enough to check independently, attributed to a speaker who must themselves be identifiable, linked to a specific segment of the source material, and explicit about uncertainty or non-verifiability.
Correctness in this system does not mean 'sounds plausible.' It means the system can show exactly where the claim came from and explain why it was or was not checked.
Initial Approach (Naive Real-Time Pipeline)
The first iteration of this project was built as a real-time system, leveraging the same infrastructure I had already developed for streaming speech and structured parsing (Schma.ai).
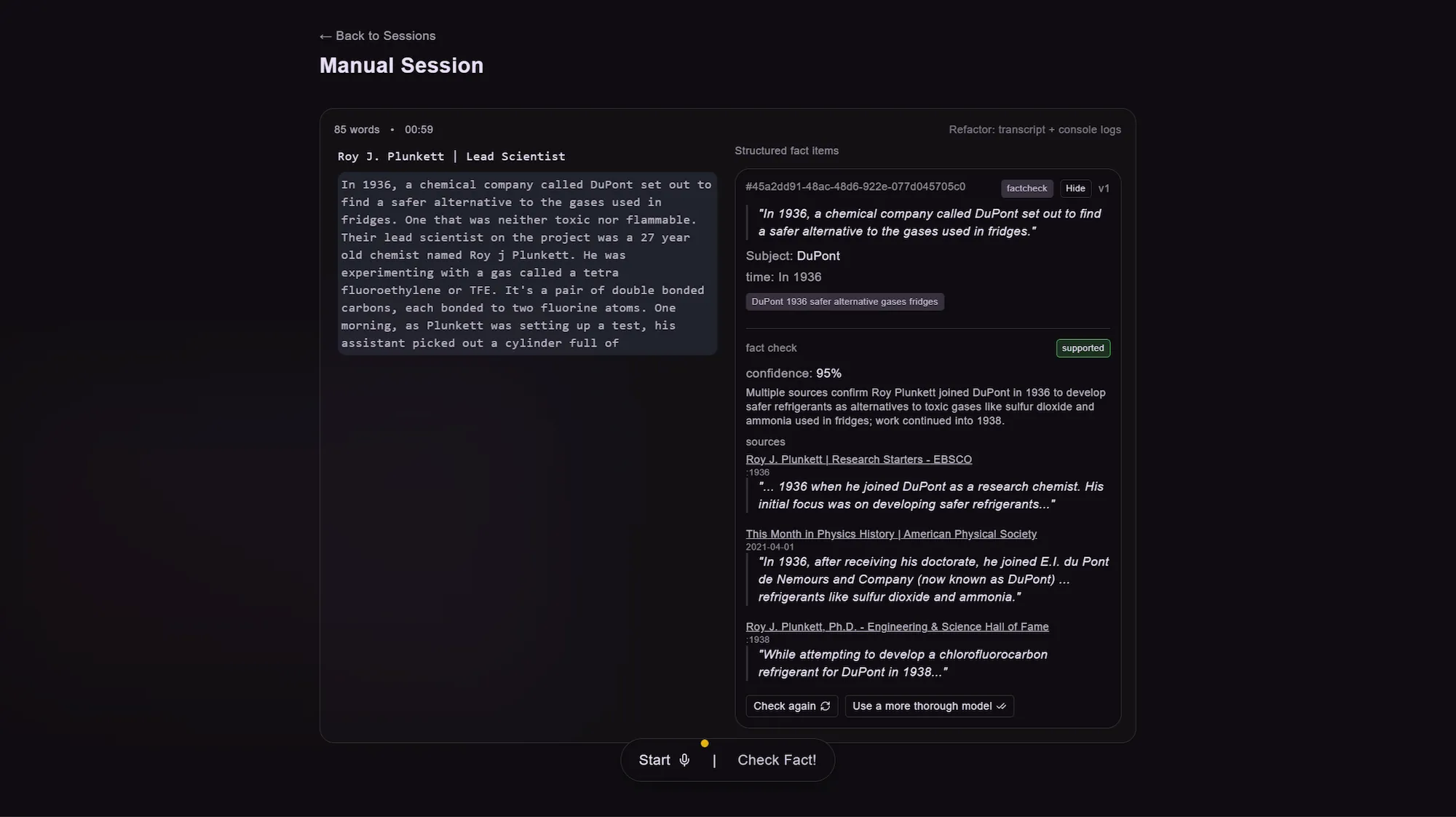
Input & UI: Voice as the primary input, real-time, diarized transcription, and a SaaS-style dashboard with live transcript view, speaker attribution as the transcript progressed, and a manual 'check fact' trigger (this was a bit of a hack and not a great user experience).
When triggered, the system generated a fact card linked to a specific region of the transcript. Each card displayed: The extracted claim, any additional inferred context, generated search seeds, and verification results returned from an external search-based model.
A working demo of this flow exists and is used to illustrate the system's behavior.
Naive Pipeline Design
The initial pipeline relied on multiple LLM calls with distinct responsibilities: 1) Claim extraction call - Extract a candidate claim as a structured object, attempt to resolve the subject, and attach transcript references. 2) Context summarization call (less frequent) - Maintain running conversational context and provide framing for later extraction. 3) Qualification & search-seeding call - Determine whether the claim appeared verifiable, add missing context if possible, and generate search seeds. 4) Verification stage - Query external sources using the generated seeds, prefer reputable domains and exclude low-quality sources, and return evidence and a confidence-oriented result.
Some lightweight rules-based logic was also applied to resolve pronouns by matching candidate subjects back to earlier transcript segments.
Why This Failed in Practice
Even with multiple models and careful role separation, the system consistently failed on nuance.
A failure case that stood out was attempting to fact-check US election-related content and seeing a claim made by Donald Trump attributed to Kamala Harris. Structurally, the extraction 'worked.' Semantically however...
Other recurring issues included: Misclassifying opinion or sarcasm as factual claims, treating rhetorically framed statements as verifiable, producing claims that were technically extractable but practically useless, and inconsistent speaker resolution under real conversational conditions.
The key insight was that even a multi-LLM approach was still too coarse. Claim extraction itself needed to be treated as a first-class, standalone problem.
Refined Direction: Claim Extraction as the Core Product
The most defensible and valuable part of the system turned out not to be verification, but structured claim extraction with traceability.
The refined scope focuses on: Audio ingestion (batch, not real-time), high-quality transcription with diarization, claim atomization into minimal, independently checkable units, strong linkage between claims and transcript spans, explicit handling of uncertainty and non-verifiability, grounding against the transcript as the primary source of truth, optional grounding against external or internal documentation.
Verification becomes a downstream capability, not the core thesis.
Planned Batch-First Pipeline
The revised pipeline intentionally avoids real-time processing. Real-time claim verification is a long-term goal, but attempting it early dramatically increases complexity without improving correctness.
1. Ingest & Transcribe: Batch audio ingestion, diarized transcription with timestamp alignment, optional speaker resolution pass.
2. Segmentation: Split transcript into overlapping, context-preserving segments, preserve continuity to avoid context loss.
3. Claim Atomization: Use models or techniques optimized specifically for breaking language into atomic factual units. Produce structured claim objects with claim text, speaker attribution, transcript span references, qualifiers and modality, and implied entities (where resolvable).
4. Claim Qualification: Classify claims as verifiable, non-verifiable (opinion, sarcasm, rhetoric), or underspecified. Surface uncertainty rather than forcing binary outcomes.
5. Grounding & Traceability: Ground claims against the transcript itself (primary source of truth) and optional external or internal reference material. Always return citations and evidence links.
6. Presentation: Display claims as timestamp-linked cards, support replay, inspection, and human review, treat manual correction as a supported workflow.
Trade-offs & Limitations
This system explicitly accepts: Higher latency in exchange for correctness, batch processing over real-time, that not all claims should be verified, and that some ambiguity cannot be resolved automatically. Not all claims are verifiable, some are opinion, sarcasm, or rhetoric, and some are underspecified without additional context.
Sarcasm, tone, and implied meaning may eventually require acoustic analysis or additional modeling, but the pipeline is designed so those signals can be added without collapsing the system. Going deep into this stuff would require a lot of time and effort and is not in the scope of this project.
Outcomes & Learnings
The project reinforced several key principles: Claim extraction is often harder than verification, multi-stage pipelines are necessary for trust, traceability is the foundation of credibility, confidence without grounding erodes trust immediately, and real-time systems must be earned, not assumed.
Status & Next Steps
This project is currently paused while I evaluate product direction and monetization. The motivation (trust, accuracy, and accountability) remains strong, but the build cost is non-trivial.
The most viable path forward is to productize the claim extraction and traceability layer first, with verification as an optional downstream capability rather than the core bet.